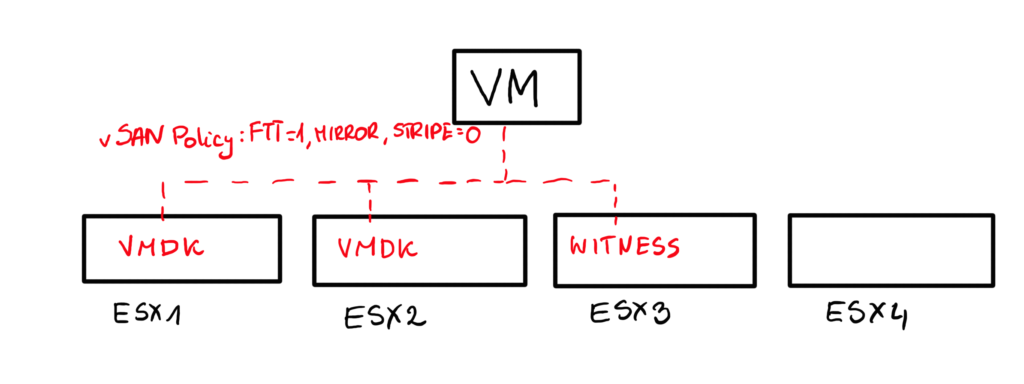
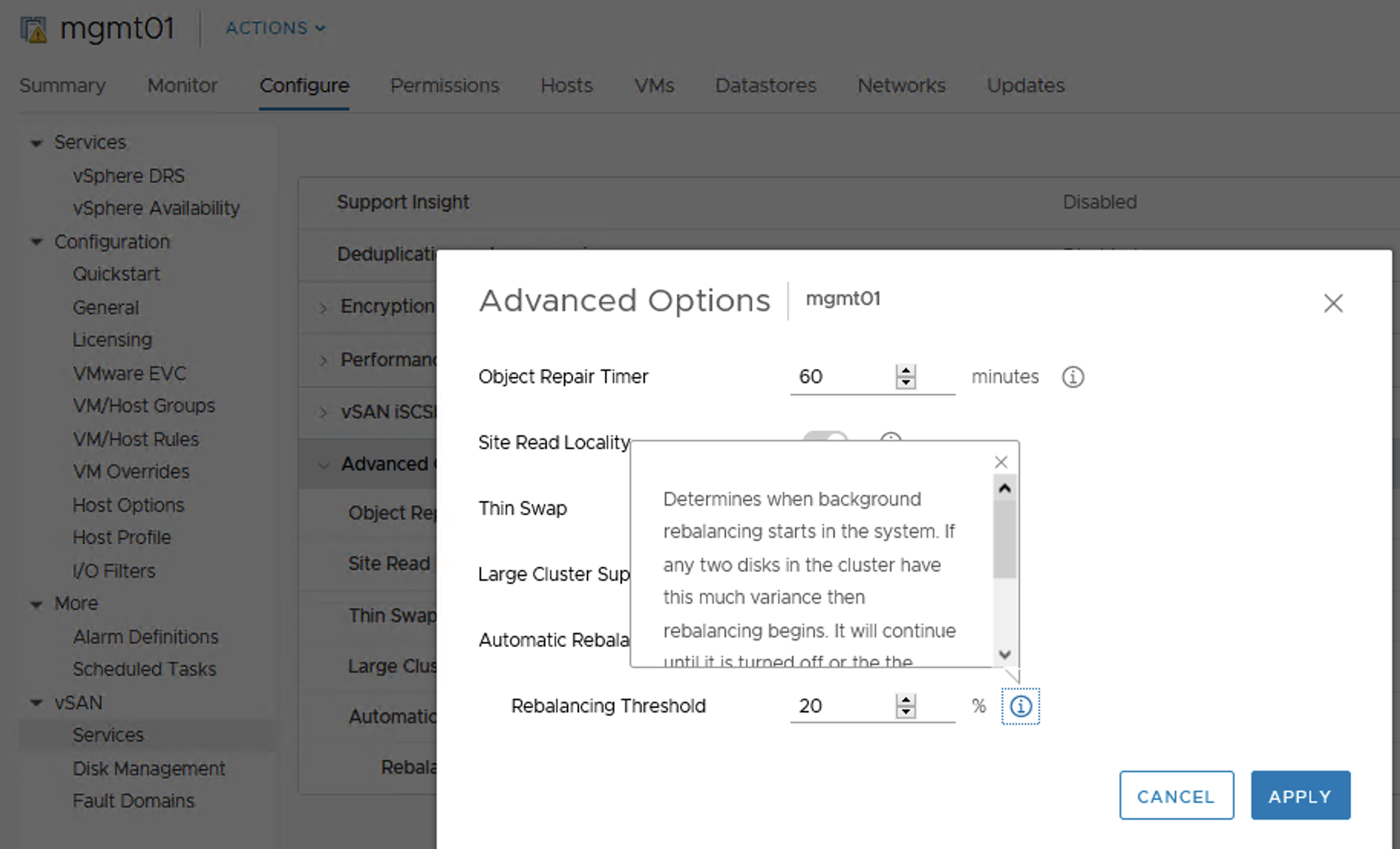
Usually when we use a basic SPBM FTT-1 mirror policy and there is no stripe involved, we end up with 2 copies of the data on 2 different hosts and additionally a component metadata on a third one per each object to avoid a split brain scenario.
Like in this example below – two VMDKs on ESX1 and ESX2 and witness metadata on ESX3. For other objects placement will be probably different.
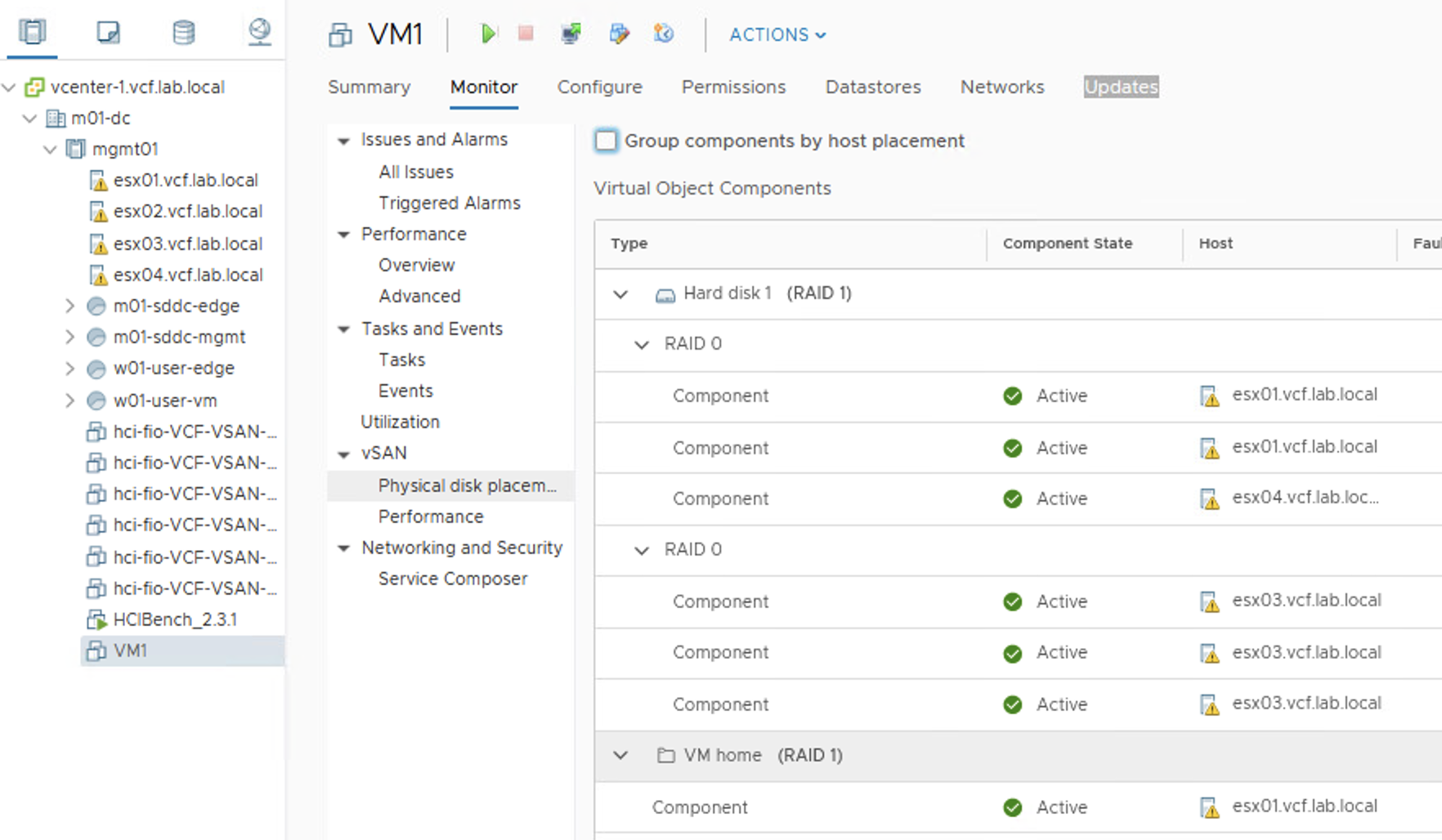
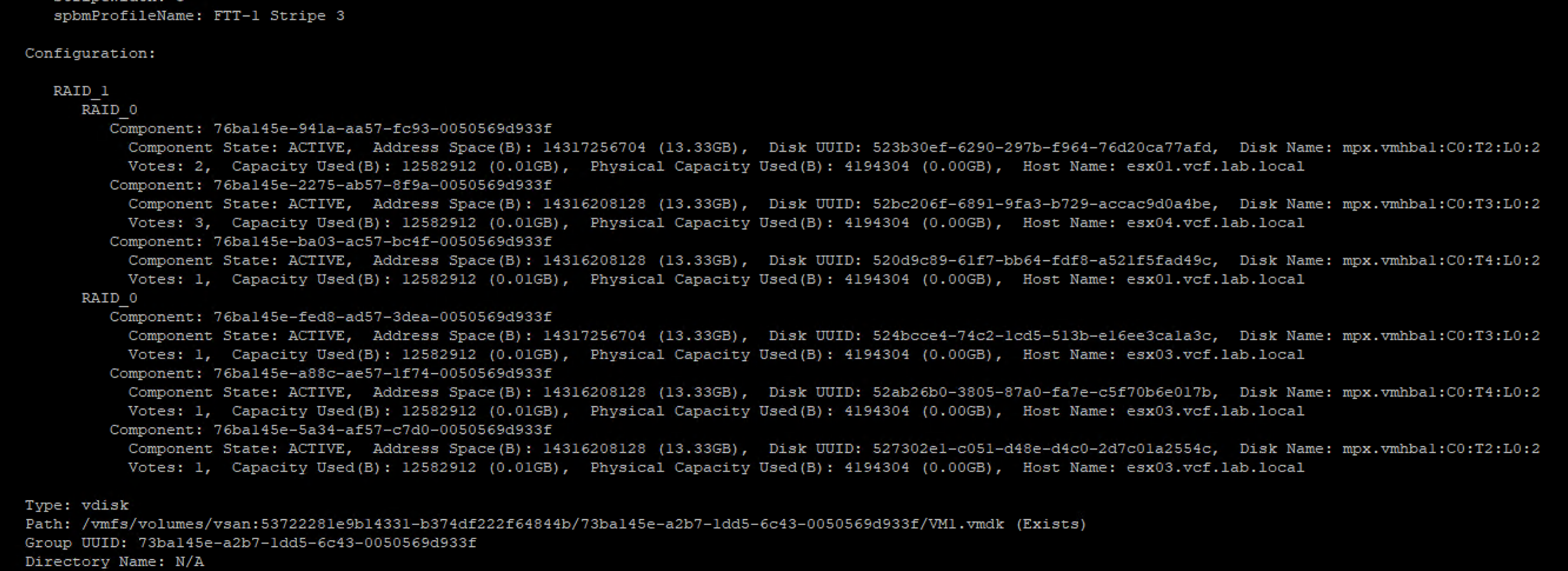
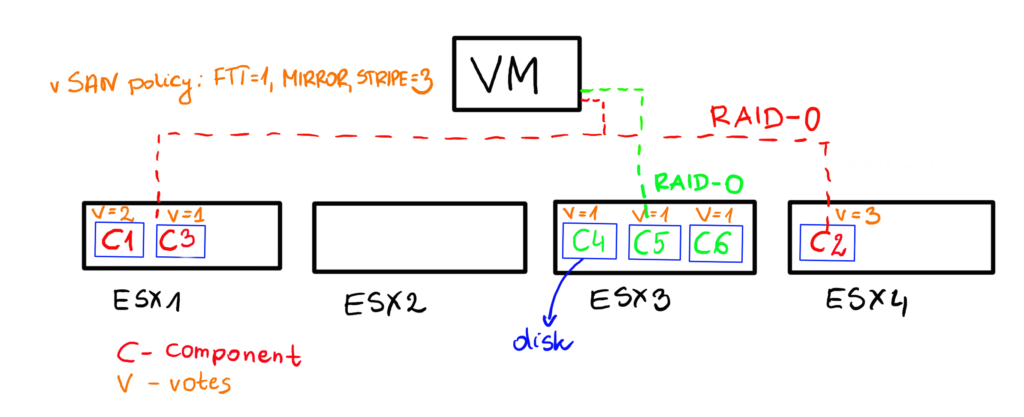
But this is not always the case. When objects are striped, witness metadata may not be needed. Here is an example of FTT-1, stripe=3 policy. One of VMDK objects is striped into RAID-0 on ESX1 and ESX4 (on 3 different disks ) and RAID-0 on ESX3 (on 3 different disks).
Here is how it looks like from the vote perspective: on ESX3 all three components have V=1, component on ESX4 has V=3 and components on ESX1 have V=1 and V=2.
In this case there is no witness metadata component required because this component distribution and votes prevent split brain scenario.
By the way, the component placement is done by vSAN automatically, we do not have to worry about votes and metadata components. But still, it is good to know how it works.
Reading Release Notes for vSAN 6.7 U3 you might overlook a very important improvement that was introduced with this release: Increased hardening during capacity-strained scenarios.
“This release includes new robust handling of capacity usage conditions for improved detection, prevention, and remediation of conditions where cluster capacity has exceeded recommended thresholds.“
The question: what happens when vSAN datastore gets full, is a very common one but rarely we have an option to test it. Every admin knows that monitoring free space on EVERY datastore is critical but it doesn’t mean we are not curious how the system reacts when datastore gets full.
Long story short – vSAN has always handled it very well but with 6.7 U3 we get lots of additional new guardrails. I always wanted to test it and now I have some time to do this.
How to fill a datastore with data? Usually I am using HCI Bench that creates lots of VMs with lots of thin provisioned VMDKs and let it run for a while.
First signals
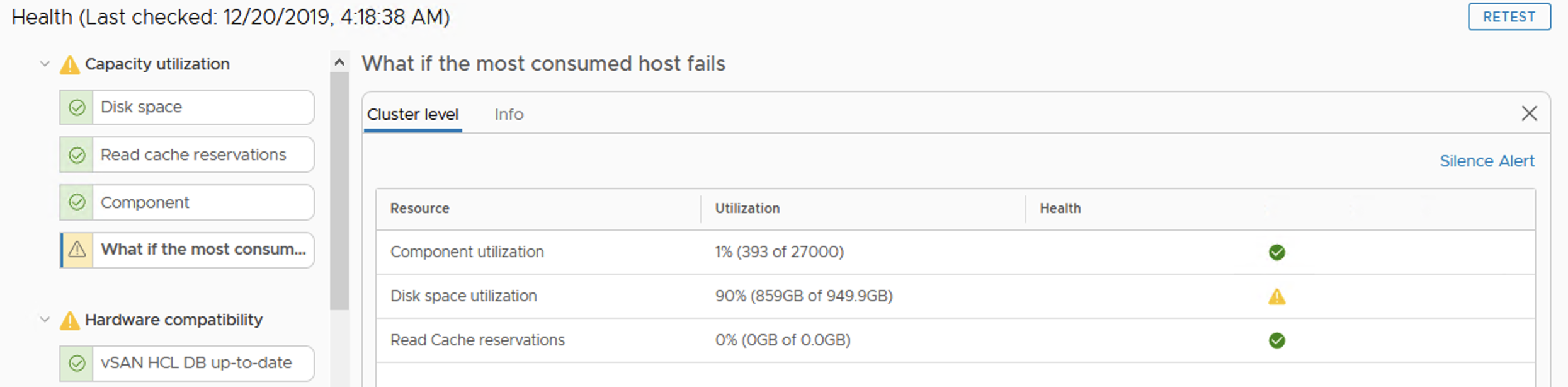
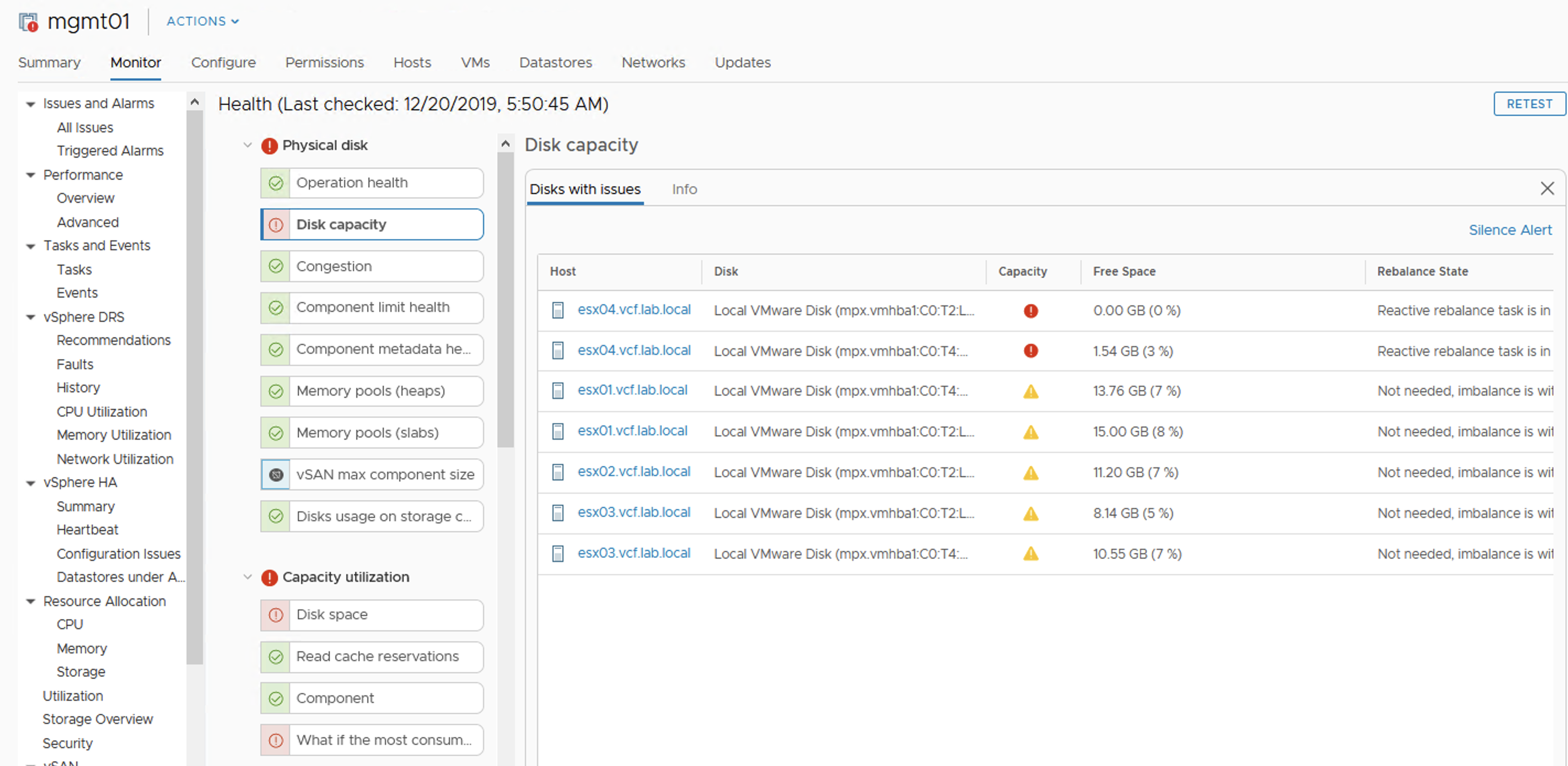
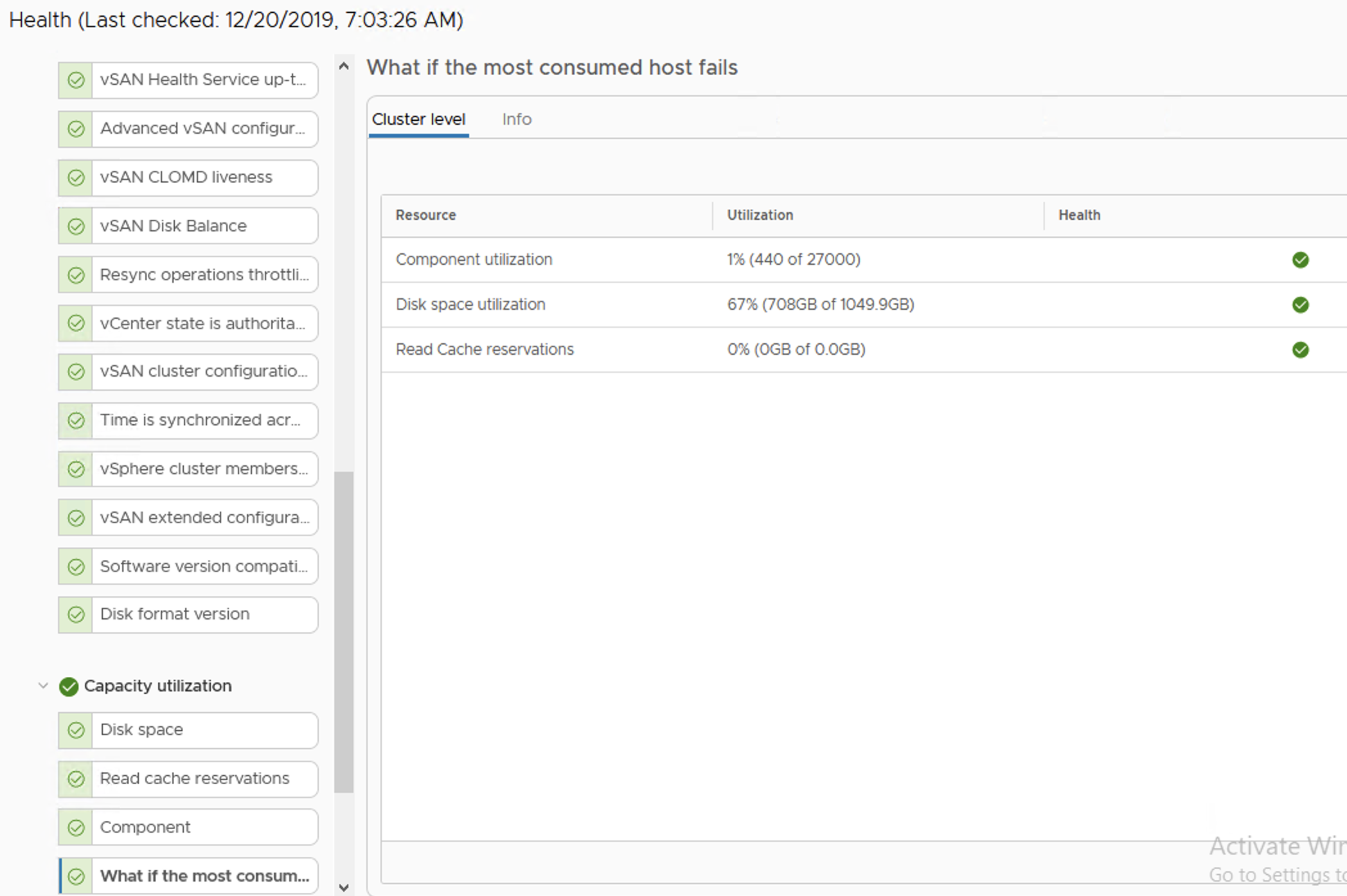
We are informed in a very early phase that something is going on with our datastore. vSAN Health shows a Warning that if we now loose one of the hosts in a cluster, disk space utilization will be high.
vSAN HealthvCenter view
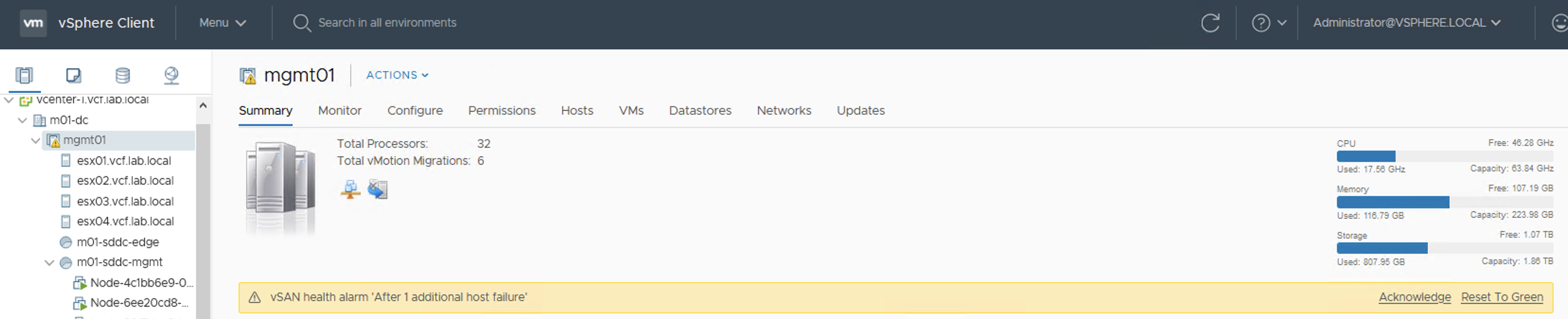
Because more data is filling up this datastore, a Warning turns into an Error. With one host offline there will be no free space on datastore to create VMs. Datastore size doesn’t seem to be full now but this is a summary of all of the datastores in the cluster, not only the vSAN datastore.
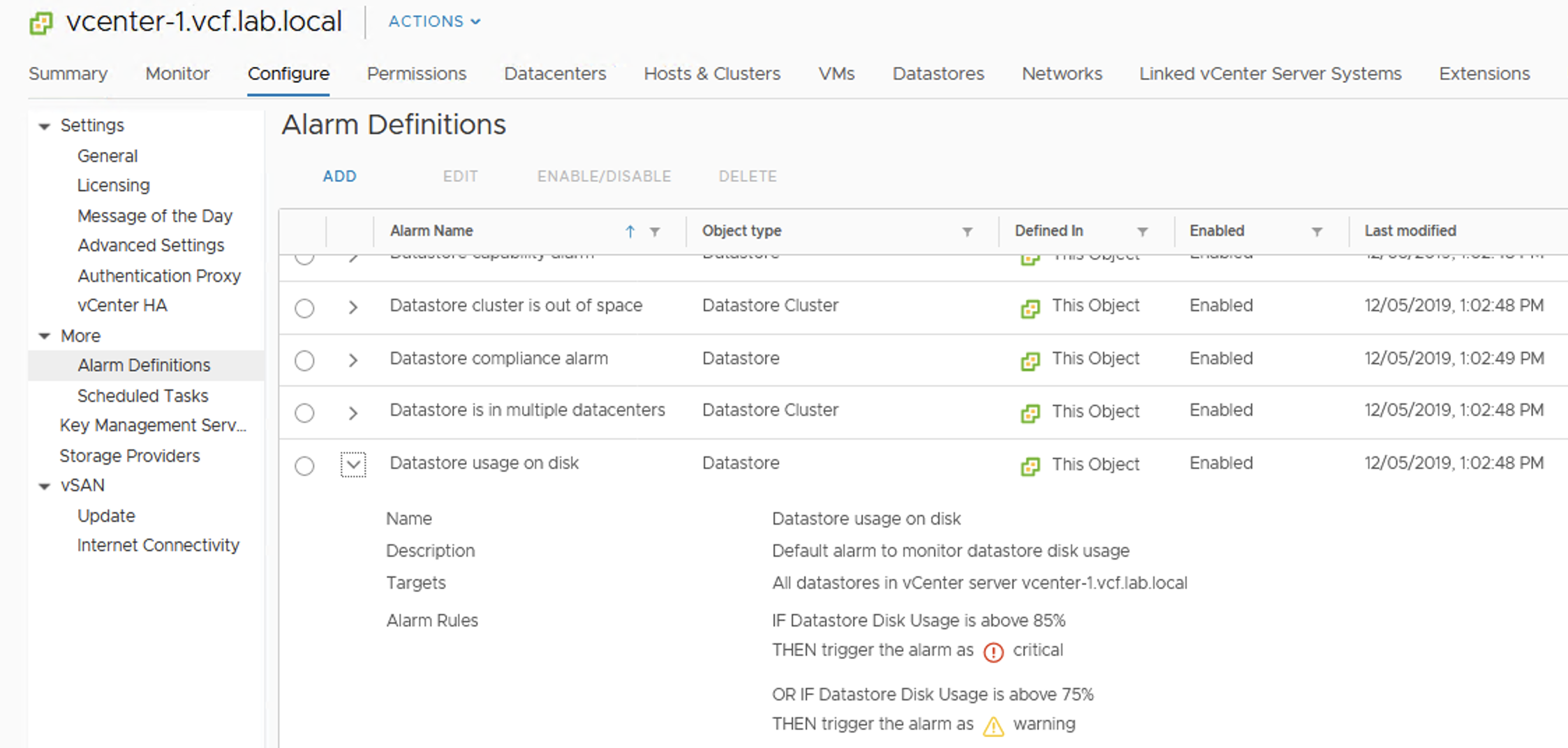
End now a very popular datastore alarm appears: “Datastore Usage on disk”. It is the same for VMFS and for vSAN.
Datastore viewvSAN Capacity Overview
If we do not modify alarm settings, we will get a warning at 75% usage and Critical at 85%.
vCenter Alarm definitions
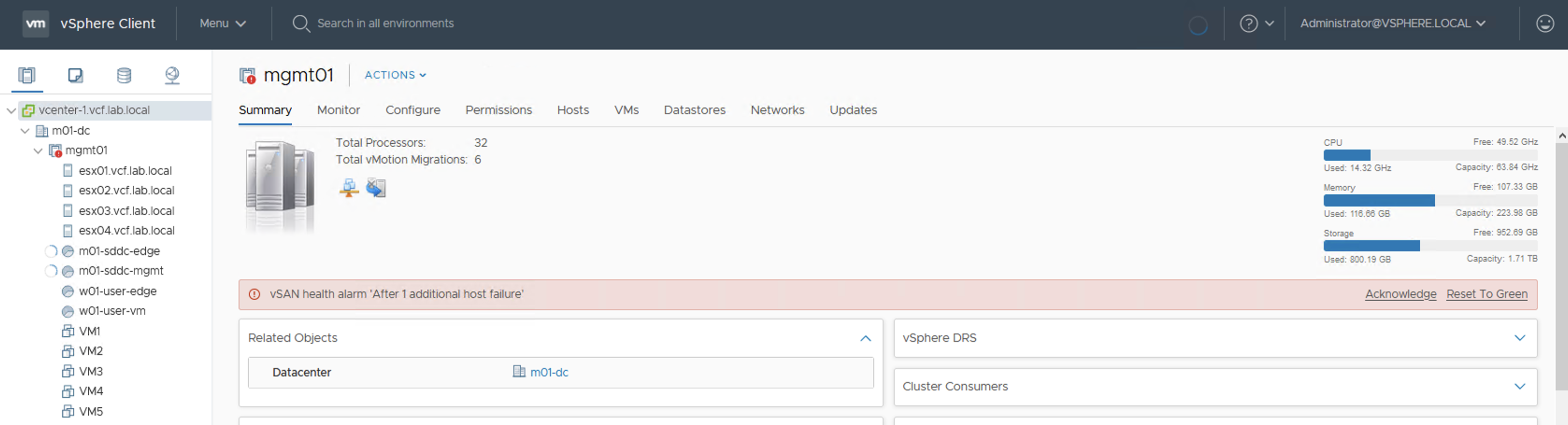
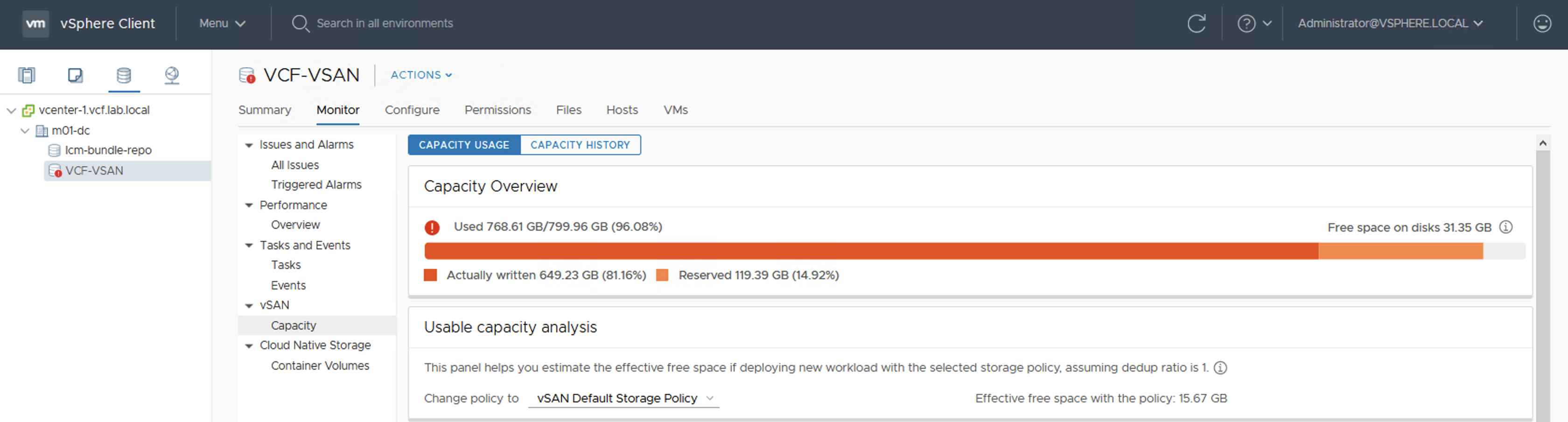
And here it is …
Datasore view and vSAN Capacity view turned red.
It is getting serious
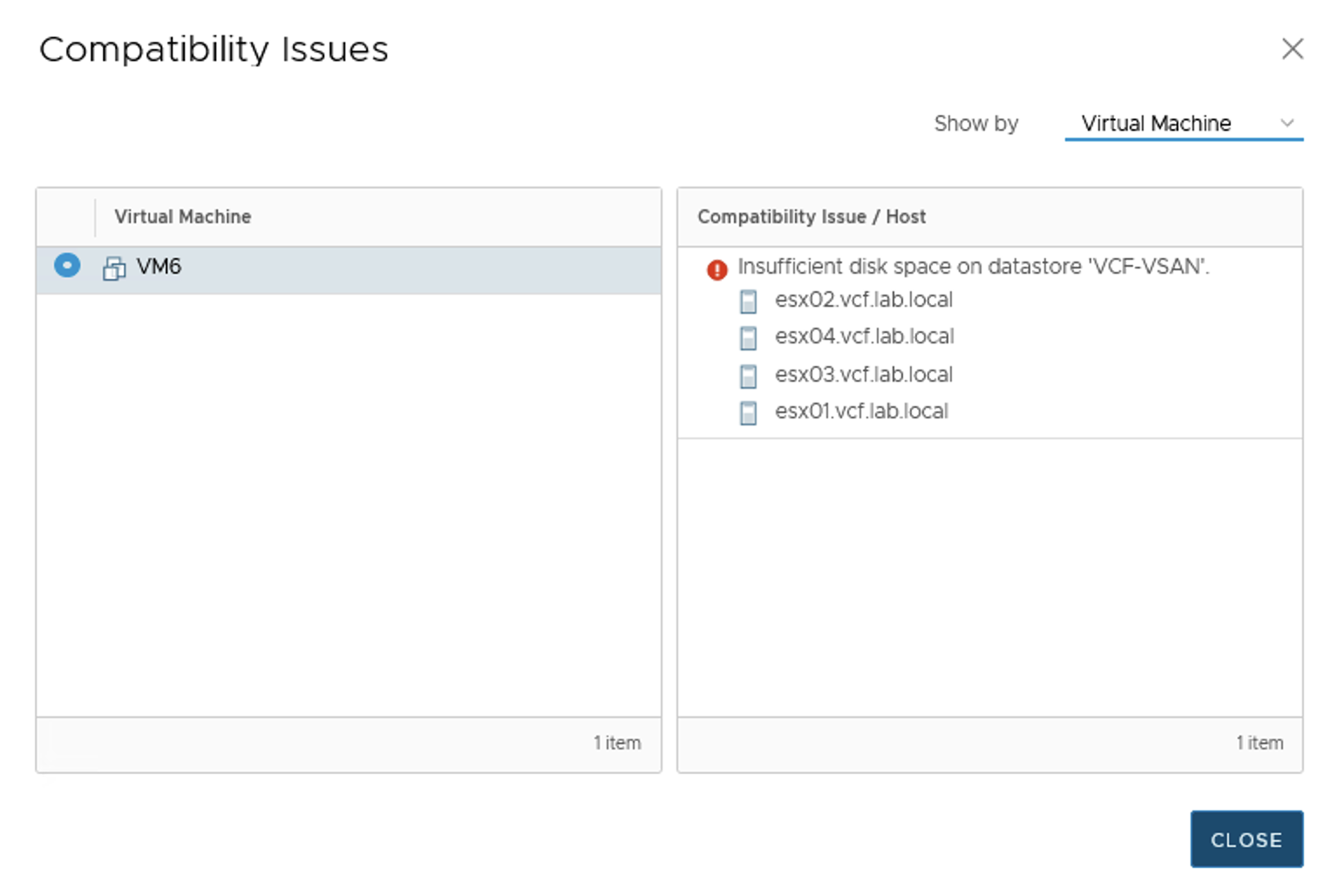
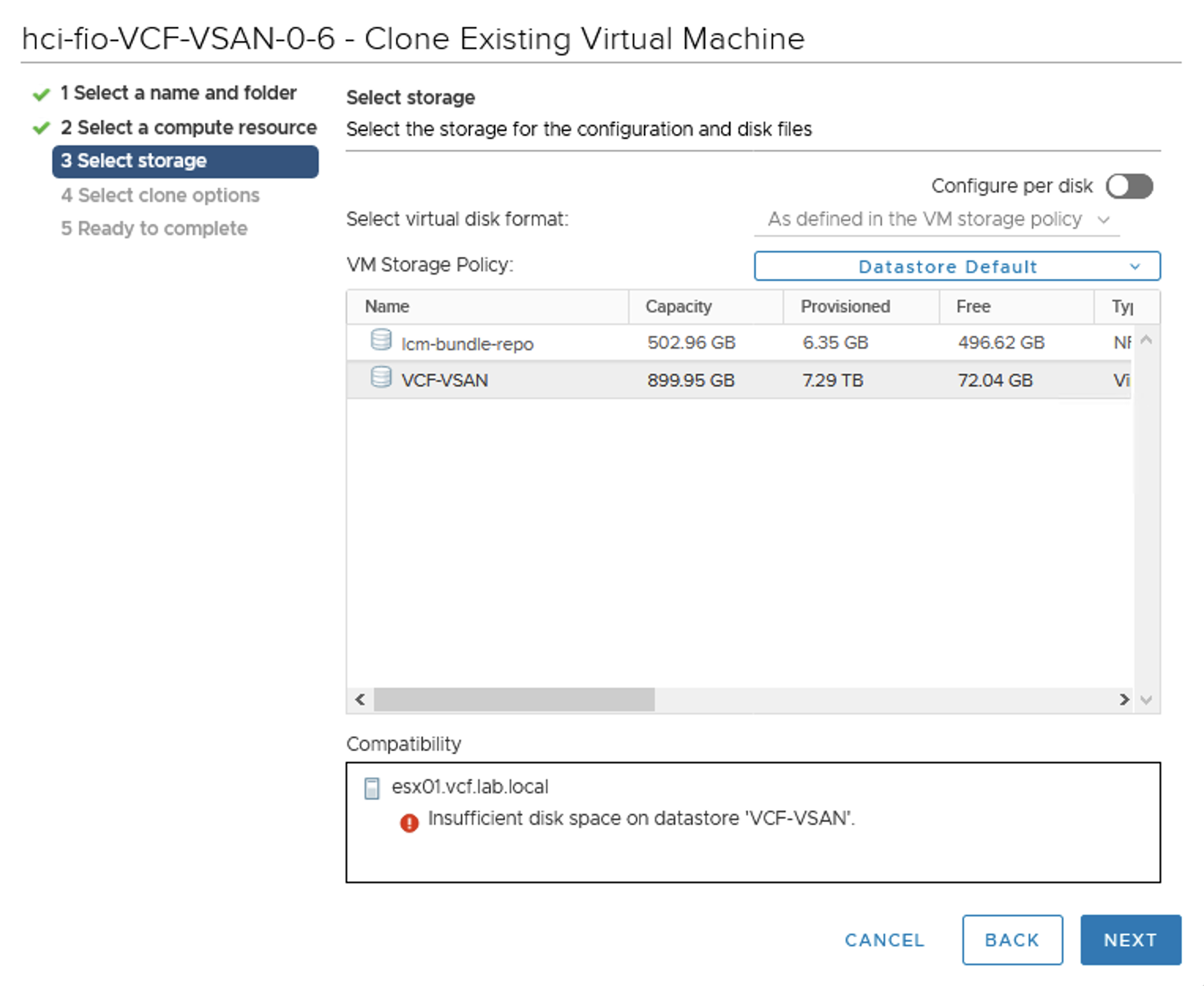
VMs are working fine (especially those that do not write to disks much) but at this point we will not be able to create new VMs (+ FTT-1 mirror policy requires 2 copies of data ).
Or clone a VM.
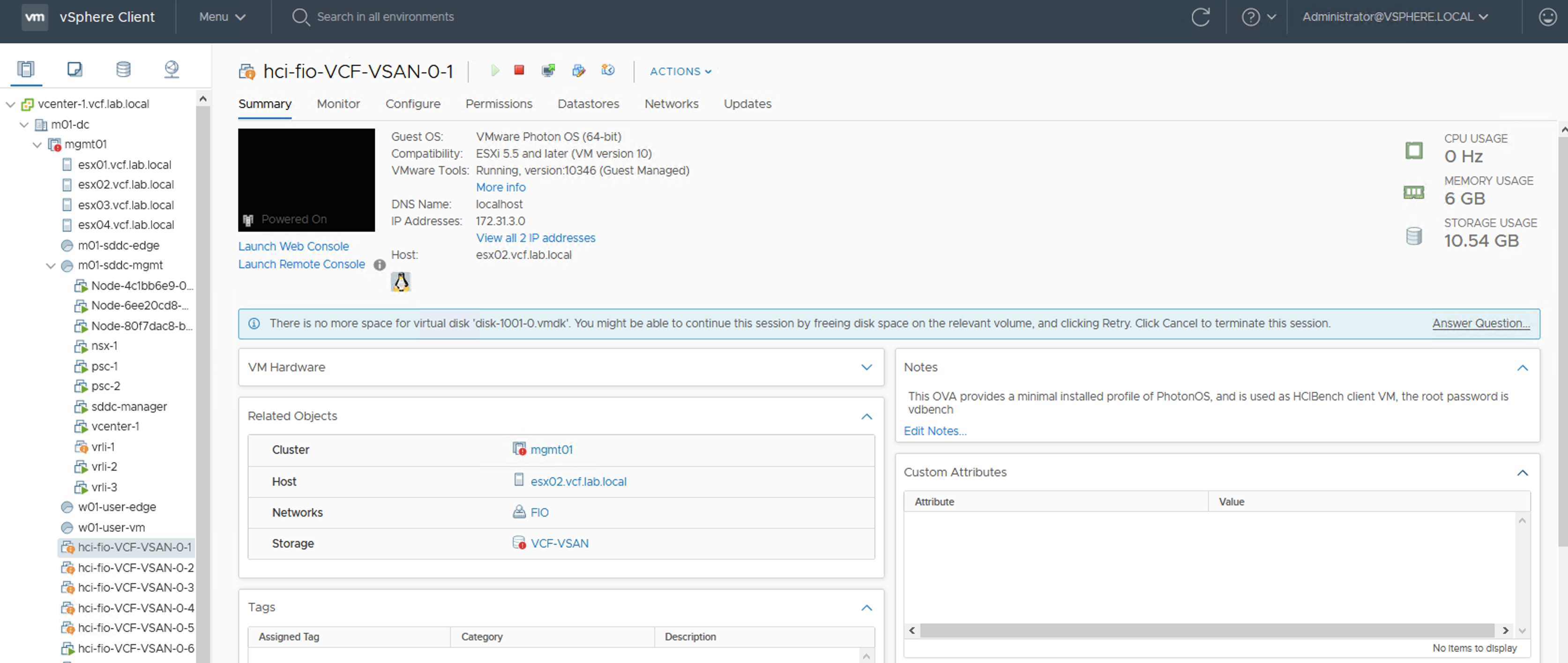
Now some of thin provisioned VMs are stunned. I deliberately run fio 100% sequential write test on them to invoke this process. It looks like datastore full test affected also my vRLI VM that was probably writing new datastore full logs on its VMDKs. Other VMs run fine.
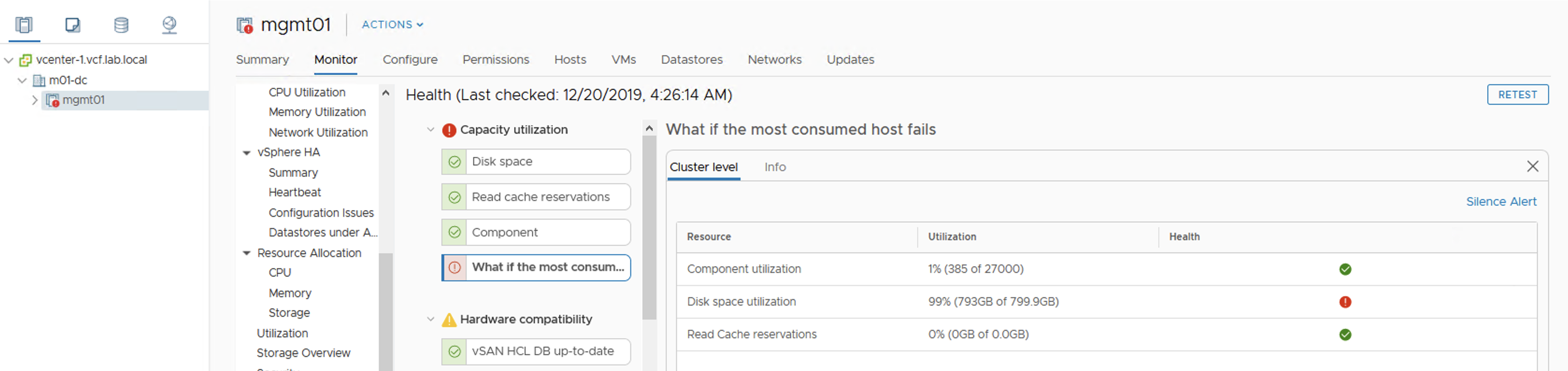
Quick check on vSAN Health:
At this point rebalancing is scheduled but not running, because datastore is getting full so there is no point in doing this. It looks like vSAN will not allow to get 100% full, it queues some activities. Hosts are fully responsive, vCenter as well. I am able to power off VMs, run some management activities. Well done vSAN!
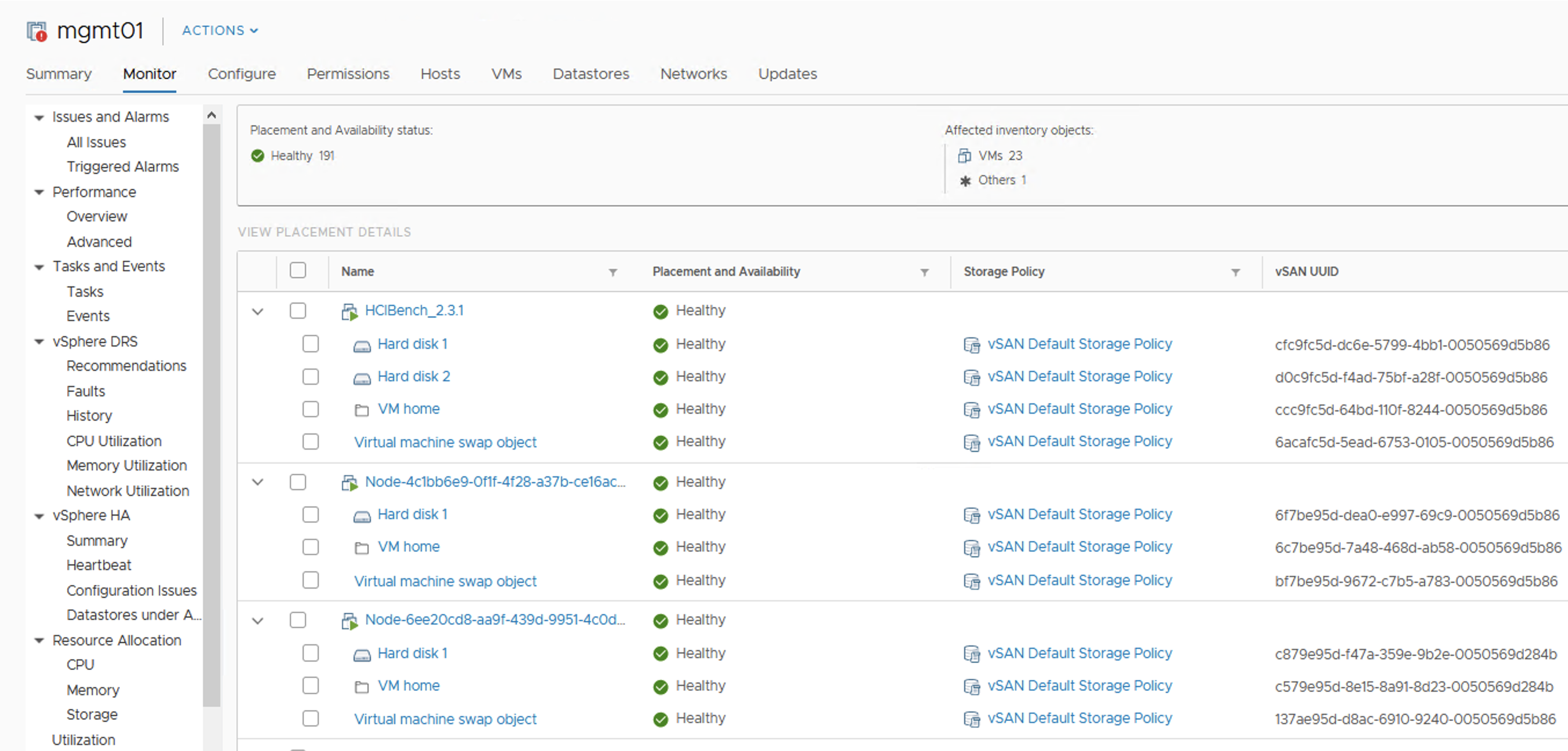
Datastore is almost full, but objects are healthy
Ultimate test
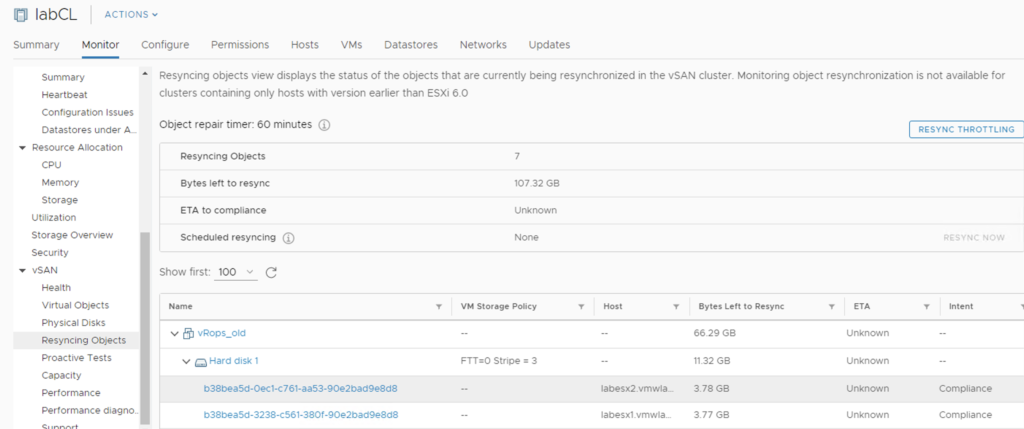
Ok, let’s get one of the hosts offline. I was not able to evacuate all data from the host because of the lack of free space, so I used “Ensure Accessibility” option. Objects are still Healthy but some of them that had components on the esx04 have just lost one copy. I tried to force rebuild them, some of them actually did rebuild but then process paused. vSAN really guards the last free GBs for the sake of the health of the whole cluster.
How to get out of it?
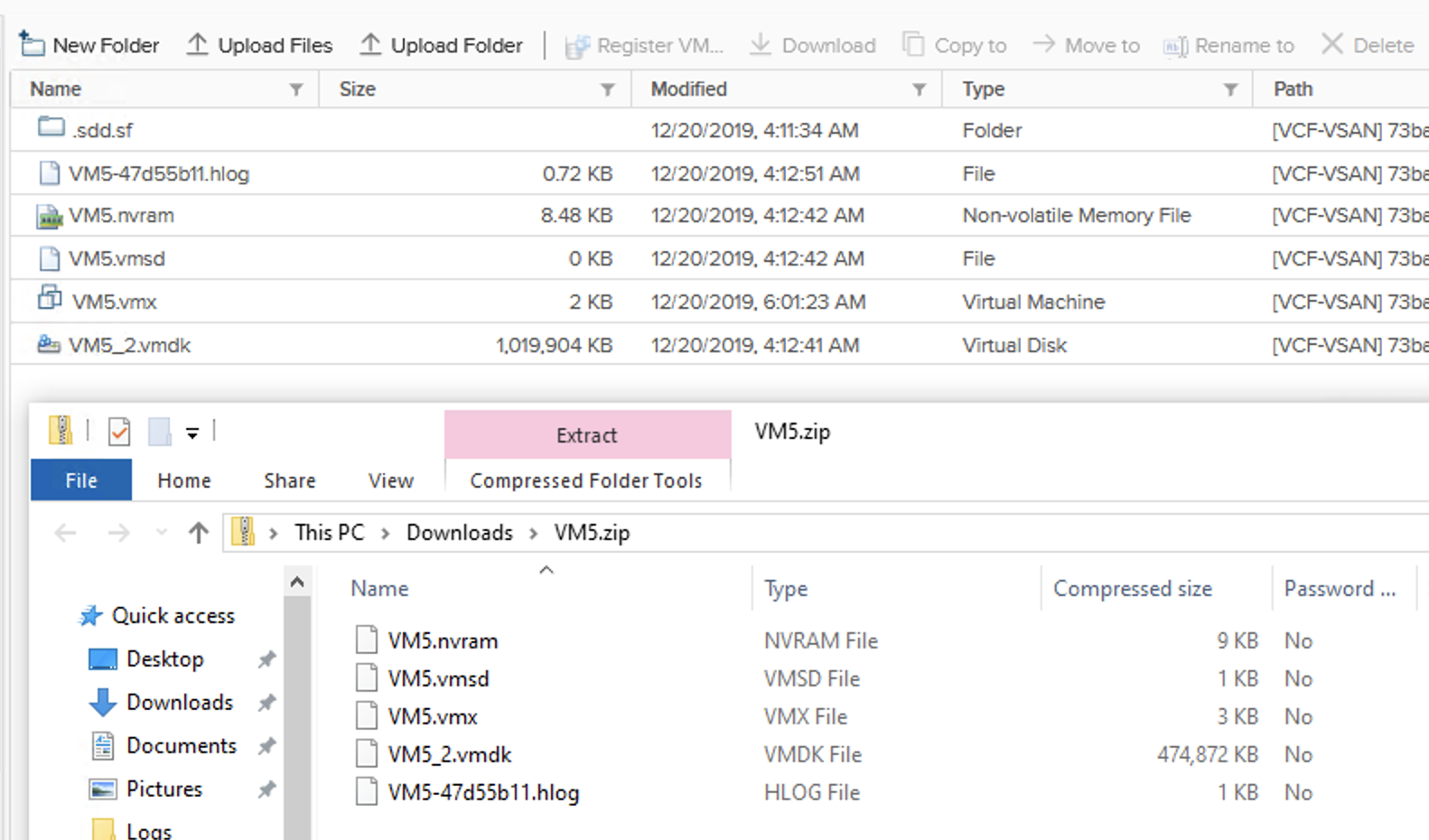
Exactly the same way like we do with VMFS. We can power off some VMs (free some swap, but it is thin provisioned so this may be not enough), we can delete VMs (bad idea in production) but we can also…download a VM from vSAN Datastore. In 6.7.U3 it finally works! 😉
The VMDK on the datastore will be twice as big as downloaded one for VMs with mirror storage policy. My VMDK is around 500MB.
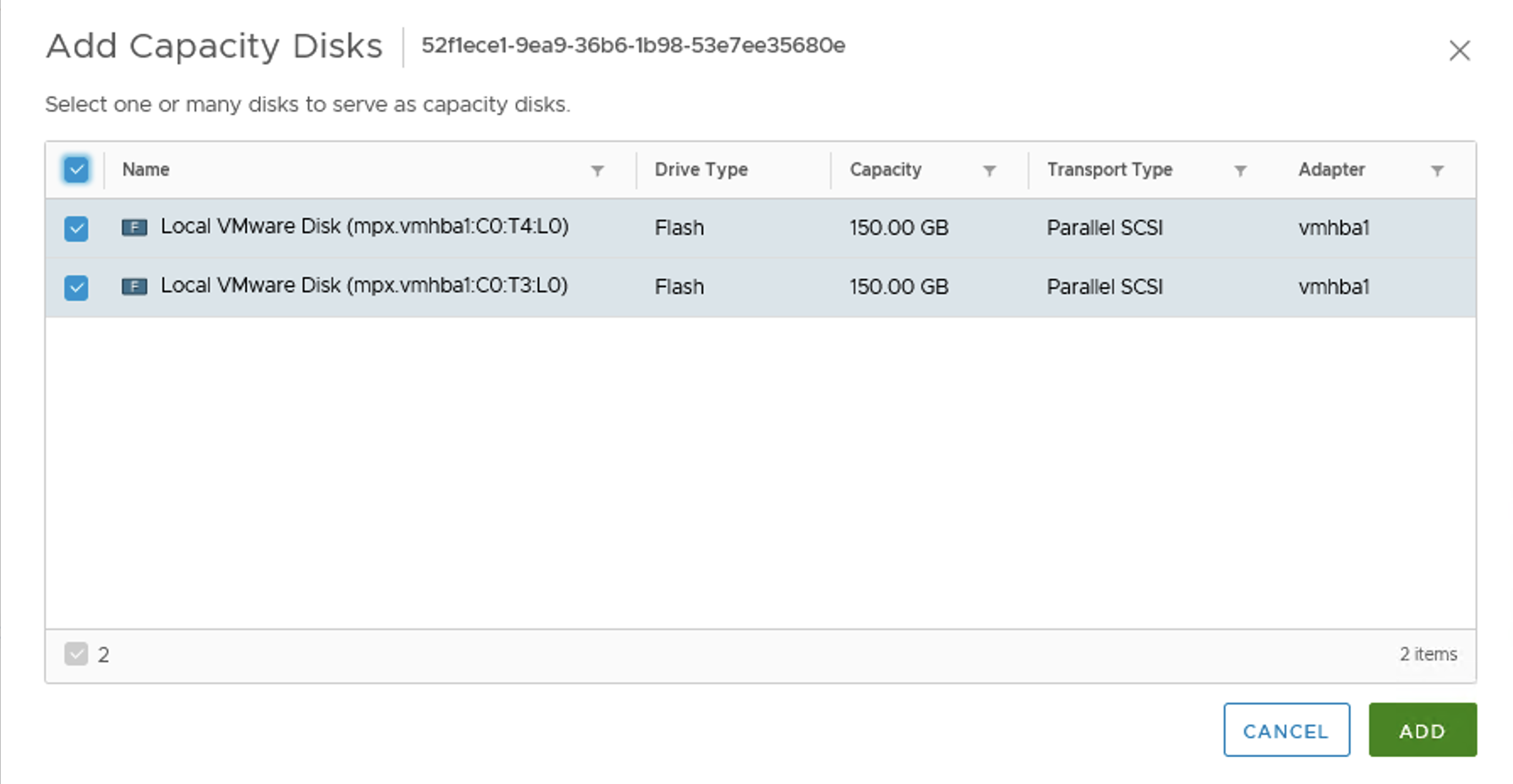
We can also add capacity disks to our vSAN disk groups to get more free space.
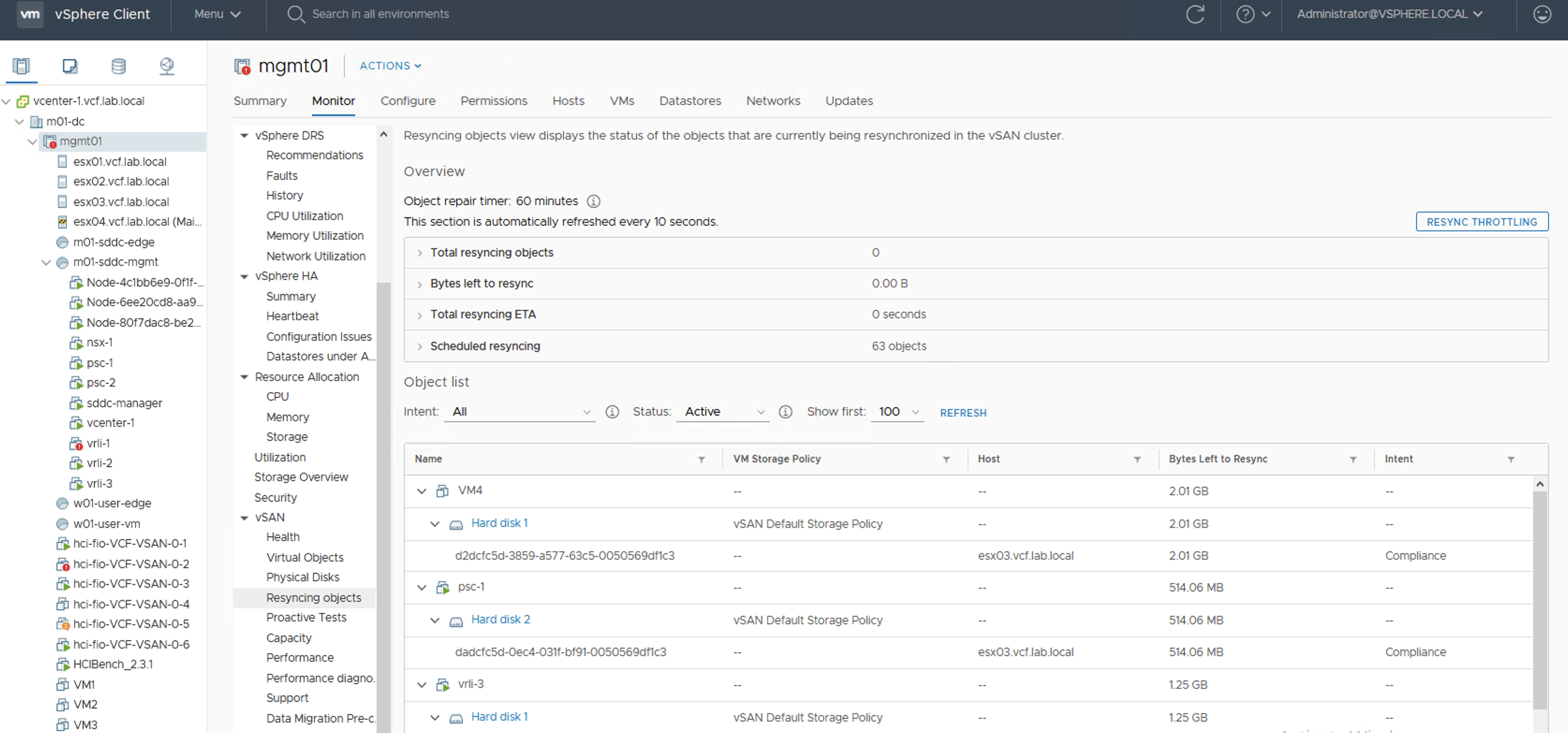
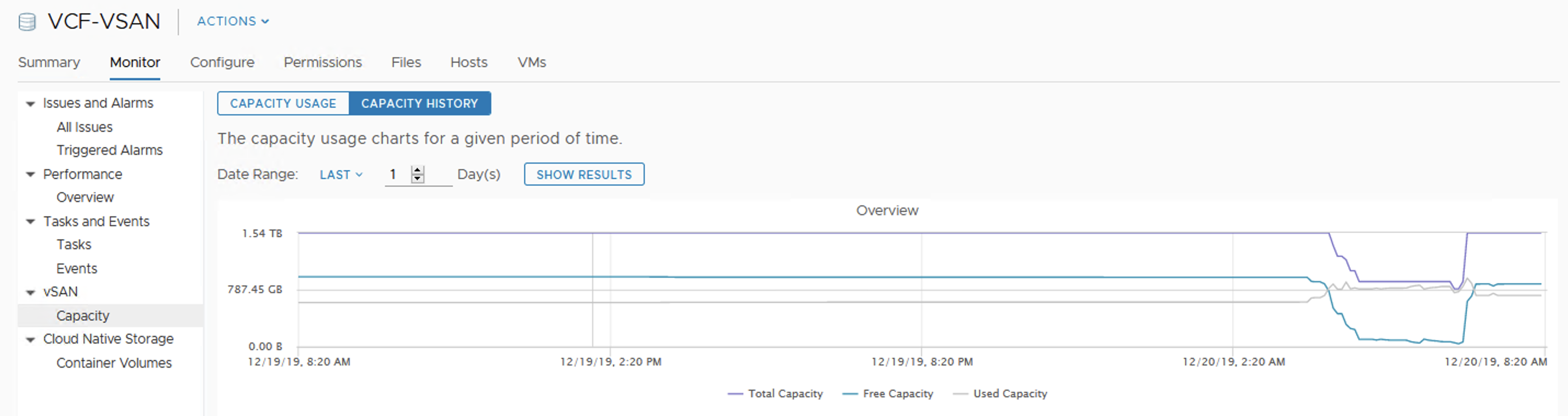
vSAN capacity history
After we add disks the reaction of the cluster is immediate. We get more space, paused resync jobs start again, still in a controlled way, not all of them at once. Depending on our disk balance policy, rebalancing kicks in when certain threshold is exceeded.
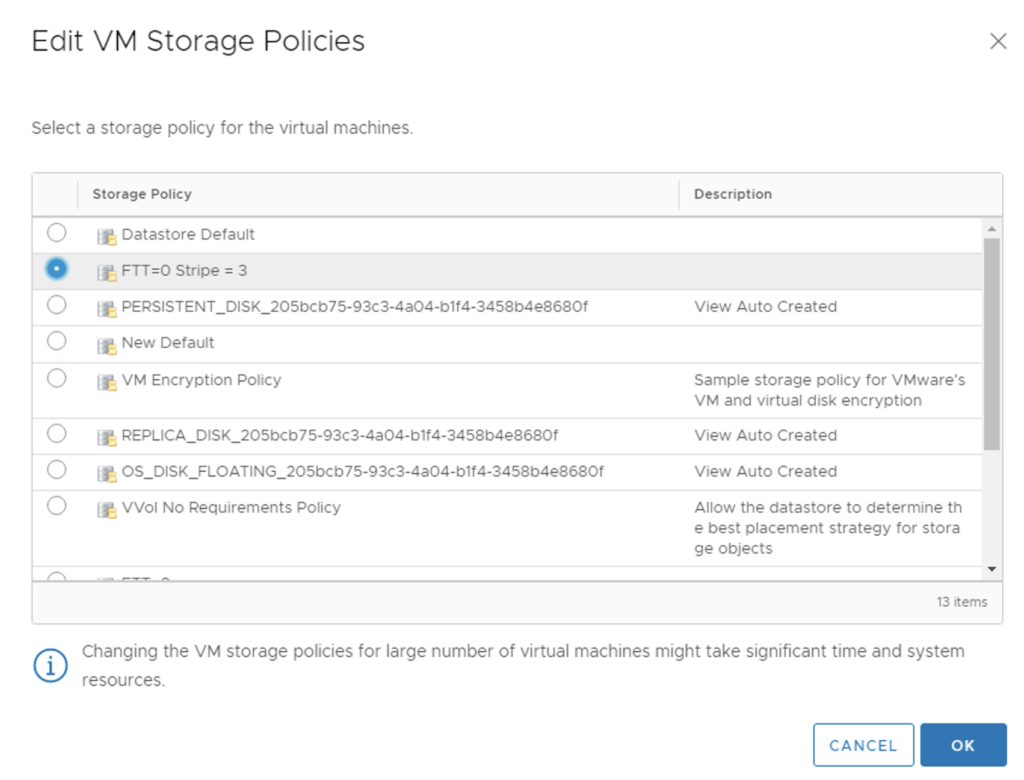
Imagine we have 100 VMs with VMDKs attached to a vSAN Default Storage Policy (RAID-1) and we want 20 VMs to move to a new FTT=0 Stripe-3 storage policy. We can create a new policy and apply it to VMs one by one. It may be a reasonable approach not to change it for all 20 of them at once…but if in vSAN 6.7U3 VMDKs are finally processed in batches, we could give it a try 😉
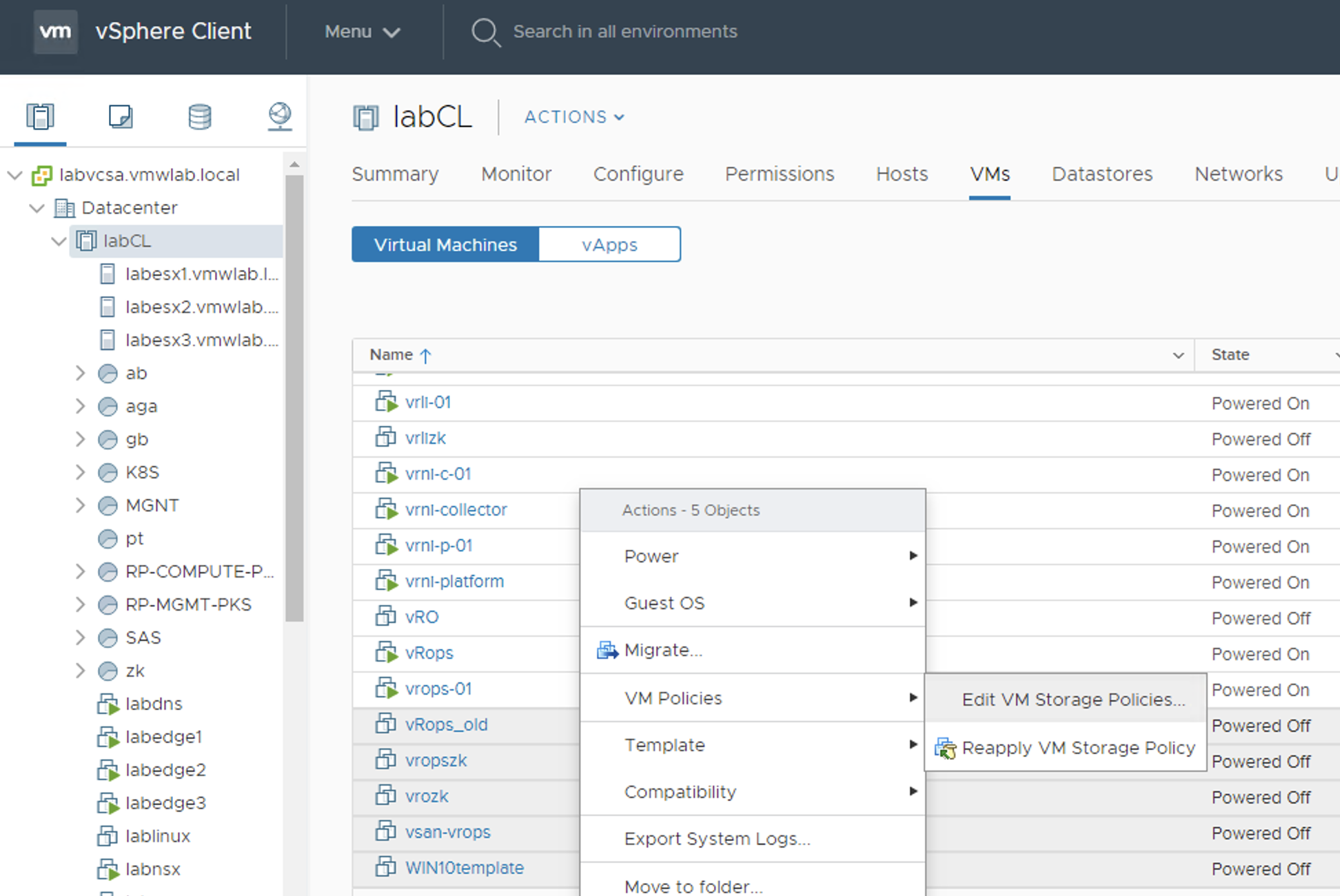
So the trick is simple. We go to the VM folder on the Cluster level and use Shift to select desirable number of VMs. Obvious, isn’t it?
There is one caveat though – we will not be able to select SPBMs on VMDK level, storage policy will be applied for all of the selected VMs for all of their VMDKs.
And than we can wait and observe our resync dashboard.
vSAN uses the concept Fault Domains to group hosts into pools. Each FD can have one or more ESXi hosts. Usually it is used to protect the cluster against a rack or a site failure. vSAN will never place components of the same object the same FD. If the whole FD fails ( a top of the rack switch failure, a site disconnection), we will still have a majority of votes for the object to be avaialbe.
If we don’t configure any FD in vCenter, every ESXi host will become a kind of FD, because we will never have components of the same object on the same host…even if the host has more than one disk group. So the smallest FD is the host itself.
In vSAN the smallest number of Fault Domains is 3 and this config will protect against a single FD failure. To protect against two FD failures using MIRROR, we will need 2n+1=5 Fault Domains, for 3 failures protection with MIRROR we will need 7 FDs.
It is best practise to place the same number of hosts into every FD.
FDs are configured per vSAN cluster.
Example 1
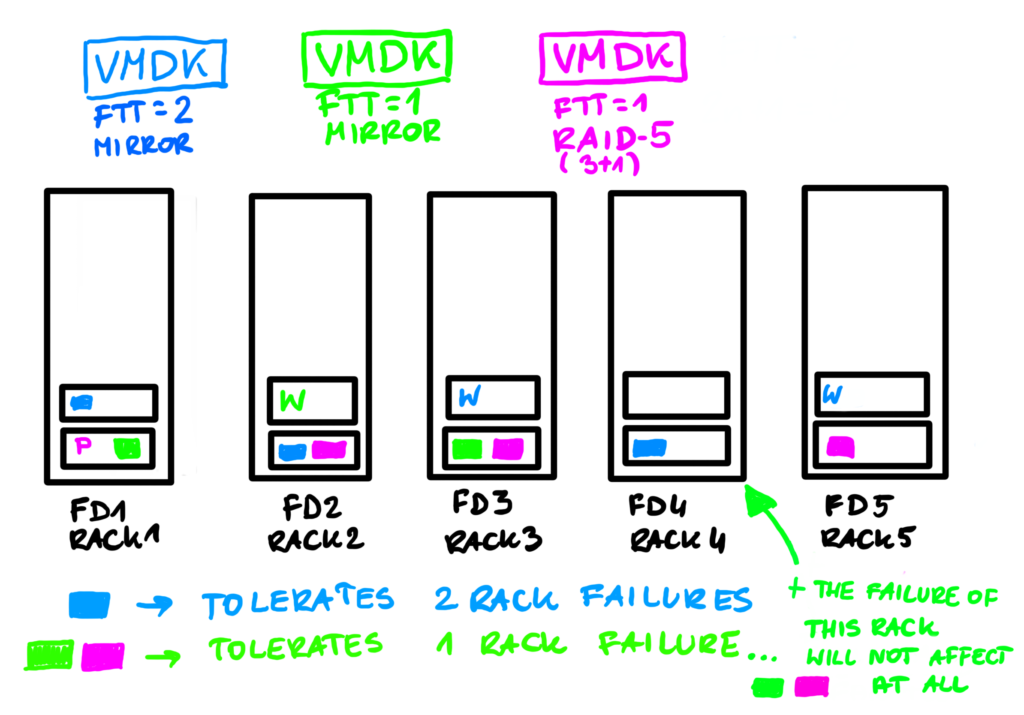
Here is a simple example. Imagine we have 5 racks and 10 ESXi hosts. We could place two ESXi per rack and this way we could have 5 Fault Domains.
Blue VMDK uses SPBM Policy FTT=2 mirror and its components are placed among 5 FDs (3x VMDK + 2x witness). Green VMDK uses FTT=1 mirror so it requires less FD than available and won’t occupy all the racks, it will use only 3. Pink VMDK uses FTT-1 RAID-5 (3x data+1x parity) and for that only 4 FDs are needed.
vSAN distributes components automaticaly, so the concept of FD might be a way to influence where the components are placed.
In this example quite by accident, the FD4 got only components of the blue VMDK. Even if green and pink VMDKs are protected against a single rack failure, failure of FD4 will not affect them at all.
Example 2
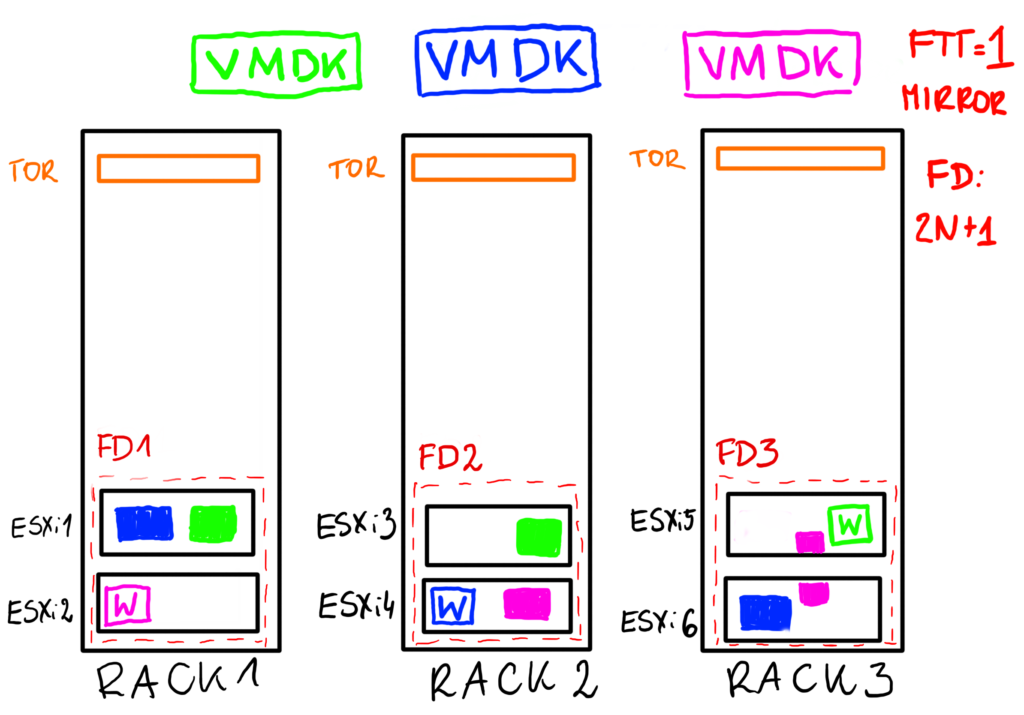
Here is another example. The smallest number of FDs is 3, so let’s imagine that this time we have 3 racks and 6 ESXi hosts. We could have two hosts per rack. FD=3 is a protection against a single rack failure. Any of the racks can fail and we will still have enough components for our objects to function. Remember, that we need to fix the issue of the faulty rack sooner or later because otherwise vSAN will not be able to rebuild a missing fault domain.
With 3 racks we could use FTT=1 mirror policy. Components are spread equally among FDs. There is no “witness” rack, witness metadata for every object can be on the same or different rack than other objects.
Example 3
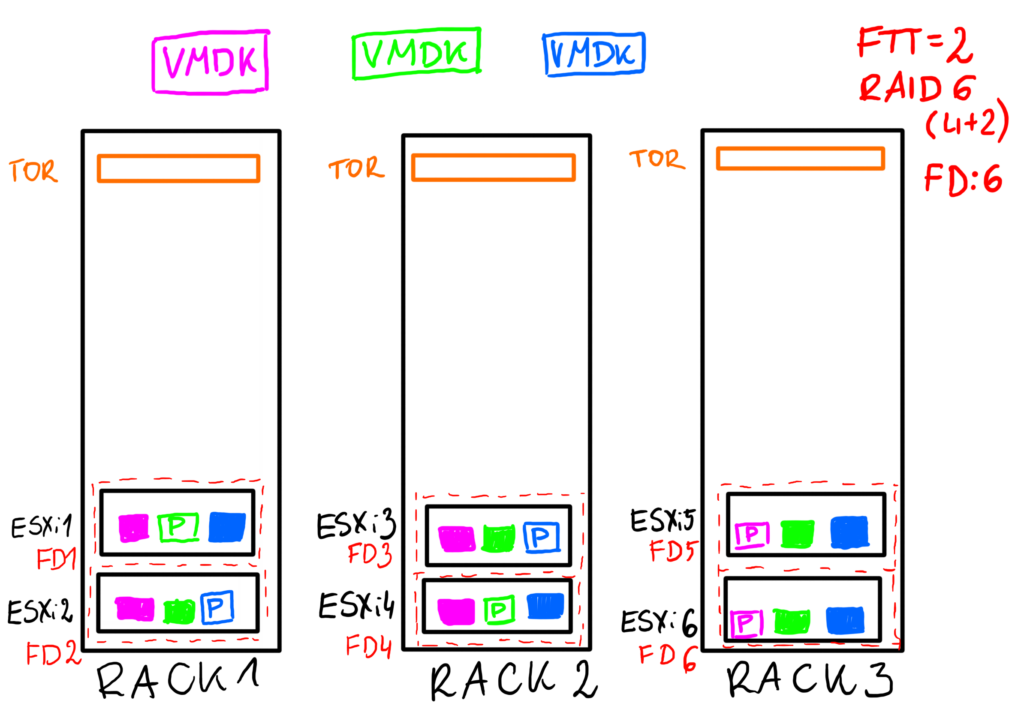
With 3 racks we could potentially use FTT=2 policy with RAID-6 (4x data + 2 x parity per data block, please note that there is no ‘parity’ component, it is here just for simplification) and with minimum of 6 hosts still be able to protect the cluster against a rack failure. It is a little bit tricky. Imagine we still have those 6 hosts from Example 2 and this time every host is a FD. The loss of a single rack equals 2 host failures and this is the max RAID-6 can protect us against.
Example 4
It would be great if we could build an environment that consists of a minimum of 2 racks that survives a failure of a single rack. But this is not possible, such an approach would require some kind of an arbiter to protect against a split brain scenario.
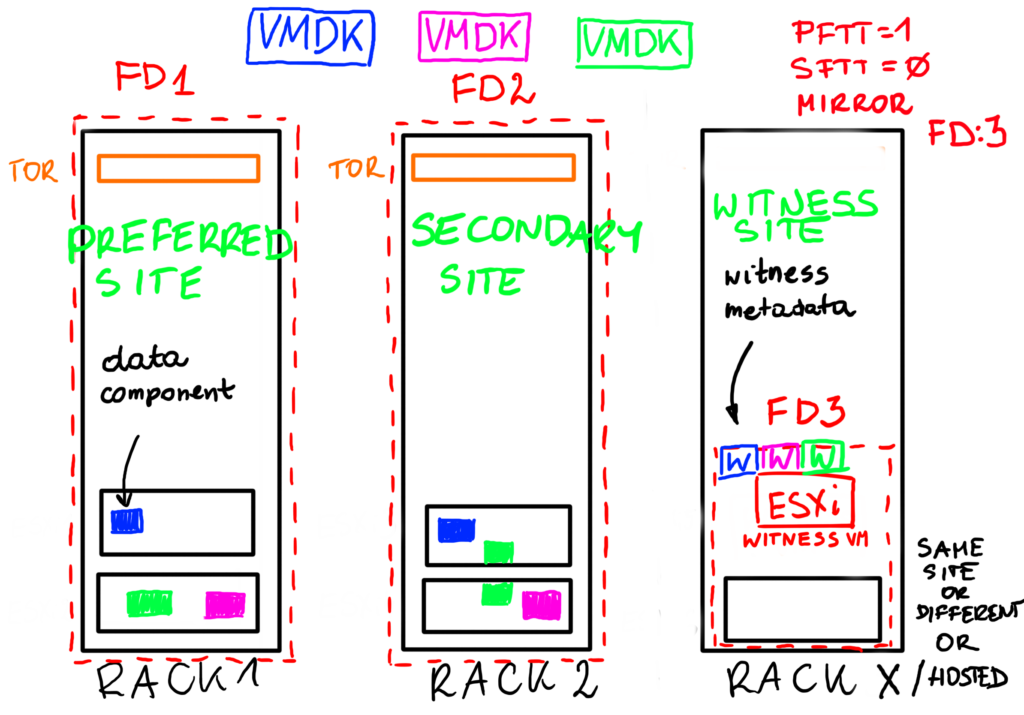
But there IS a way to do this using 2 racks, assuming witness host is our arbiter and it is hosted somewhere outside or on a standalone tower host that does not require a third rack ;-).
Yes, we can use Stretched Cluster concept to introduce a protection against single rack failure in the following way:
FD1 – Preferred Site (Rack 1)
FD2 – Secondary Site (Rack 2)
FD3 – Witness Site (outside, hosted or Rack 3)
In this case vSAN will think Rack 1 is for example a Preferred Site and Rack 2 is a Secondary Site and will use Primary Failures To Tolerate of 1 to mirror components between those „sites”. Racks may stand next to each other or they may be placed in different buildings (5ms of RTT is required). We could even use Secondary Failures to Tolerate to further protect our objects also inside a rack if we have enough hosts to do so.
In case of a Stretched Cluster we need a Witess hosts to protect the cluster against a split brain. Witness can be hosted in another rack or in another data center. Everywhere accept for Rack 1 and Rack 2.
When a host is disconnected or not responding, you cannot add or remove the witness host. This limitation ensures that vSAN collects enough information from all hosts before initiating reconfiguration operations.
It seems to be true and valid for vSAN 6.7. Is it a problem that we cannot change witness in this type of a corner case?
It would be a problem if we were not able to change witness when a host is in maintenance mode meaning that it would not be possible to replace a witness during an upgrade or a planned reboot. But we CAN change a witness in such a situation.
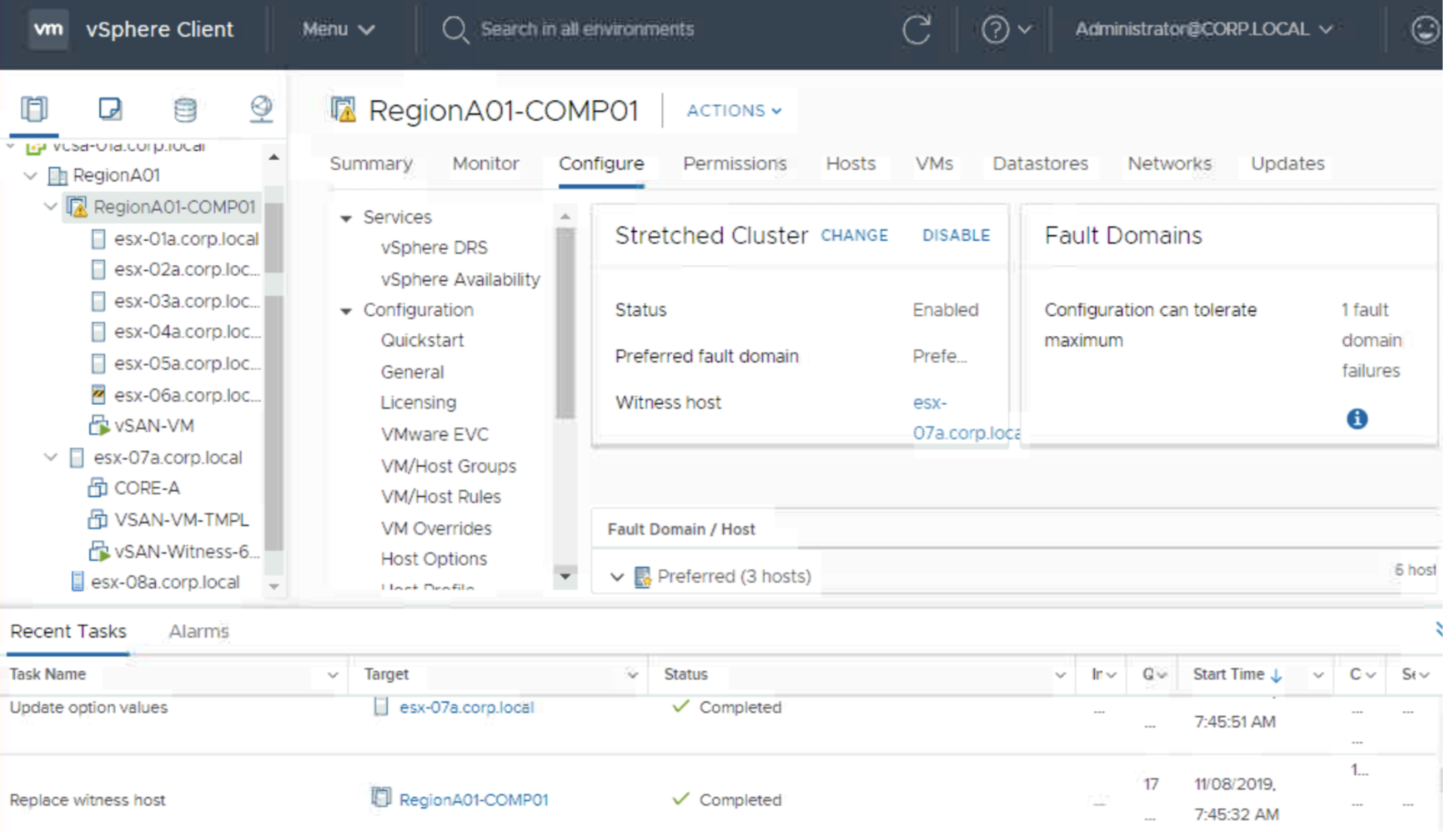
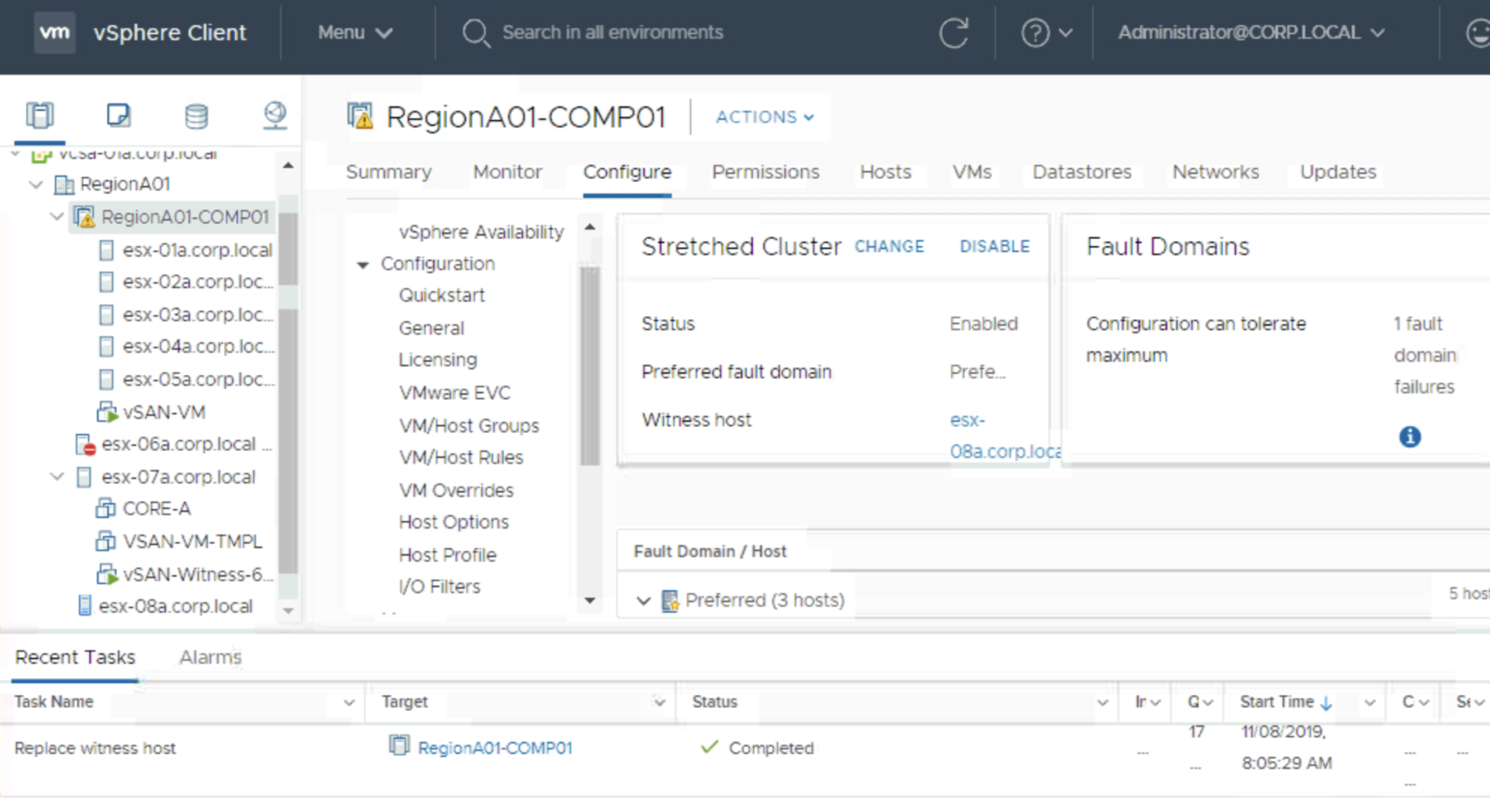
Let’s check what will happen if a host disconnects.
vCenter web guiRVC for vCenter
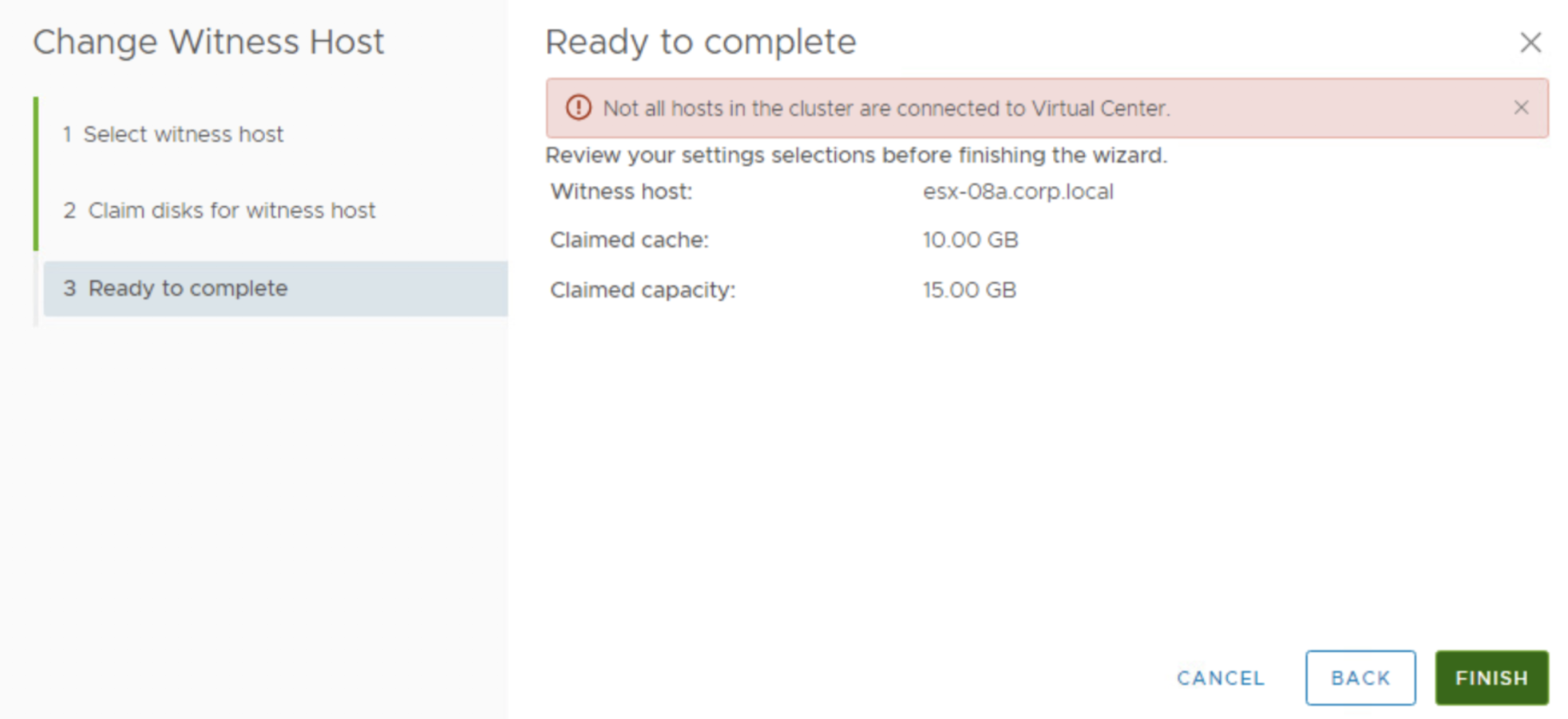
This is exactly the case described in documentation and confirms we need to have all the hosts connected to vCenter to be able to replace a witness.
Is there a workaround for a failed host scenario? Sure. We can always disconnect it and remove from the vSAN cluster and then change our witness. If a host is not available, vSAN will rebuild data on some other host anyway (if we have enough hosts), so this should not be a problem.
I have no idea why anyone would want to change witness exactly at the same time when a host is not responding. I hope to find an answer someday.
This website uses cookies to improve your experience. We'll assume you're ok with this, but you can opt-out if you wish. Cookie settingsACCEPT
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these cookies, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may have an effect on your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.